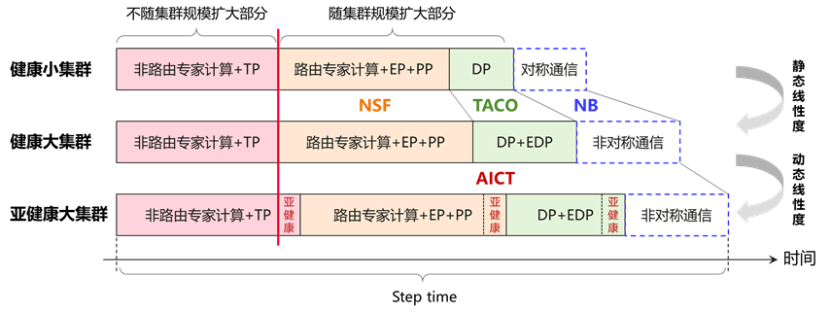
 想象一下使用您的手机导航和计划长途路线。可能有数十个AI模型背后的道路条件分析并同时预测拥塞。如果医院使用AI来帮助诊断癌症,则该系统需要立即处理数百个CT图像。在这些看似简单的智能应用程序的背后,具体取决于AI的计算机功率组,即“超级脑”,以连续运行24小时。在比较具有大型工厂生产线的AI计算能力组时,它们提供了“永不击中”此生产线并为IA计算机电源组提供“安全”的能力,使该“数字发动机”每天都可以抵抗“小型打击和吹”,并在突然的障碍物发生时保持稳定的操作。只是保证可以提供资源Reporticos,并且可以连续可用生产成为促进商业创新的可靠引擎,而不是可以离开的“半生产产品”任何时候的业务。高可用性核心基金会:失败识别,管理,容错AI,超级新生儿的大组在系统,复杂的硬件和技术电池和长期挂钩的位置中很复杂。首先,交叉域故障的限制,然后是每个域内故障的内部故障的故障和定位。残疾的诊断面临着重要的挑战。当前的定位时间在小时到几天之间不等,由于技能要求高,很难找到错误的设备或根本原因。为了帮助集群操作和维护工具,请找到问题的原因,并有效提高现有网络问题的闭环效率,华为团队提出了可观察到的全电池的可观察特征,该特征主要由集群操作的操作视图,网络的监视,对NETW的访问监控的监视ORK和网络网络操作的视图以及网络操作的视图,网络操作的视图,网络操作网络的保留,网络网络操作视图,网络网络操作视图以及网络网络操作视图以及网络操作视图以及网络操作视图。同时,完整的种马还提出了拟议的故障诊断技术,其中包括四个主要功能,包括故障模式库,跨域失败的诊断,计算节点失败的诊断和网络失败的诊断。在ITCurrent行业级别,KA级AI组平均每天失败一次或多次。这不仅对培训效率产生了严重的影响,而且大大减少了计算机资源的浪费。为了解决这个问题,华为团队通过为AI组建立完整系统的可靠性分析模型来实现可靠性指标的预期评估和分配分解s。从分析,改进,可验证和诊断方面的方面,我们继续创建可靠的系统工程功能,破坏可靠性的关键技术,并提供Supernode CloudMatrix的Wankka群集MTBF硬件的高可靠性能力。 Supernodos需要爬上超级新星,以完全利用超平面网络的好处。当前,该行业没有成功使用光学链接消费超级新生儿,因此华为设备提出了相应的超级Nonod光学链路故障容忍度解决方案。通过多层保护系统,我们使用关键技术,例如超级时代和绿色通道,以确保在超发育不良水平上无法实现故障。在链接级别的重新启动,恢复光学模块,车道和HCCL操作员,提供了铁路通信,双层路由收敛,段落级别的重新编程和其他功能,以及ToleranCE的光学模块闪光破裂的故障费用为99%。在添加了超过10倍的光学模块后,通过测量软件的可靠性以及光学链路压力的测量技术,将光学模块的闪存中断速度降低到电气链路级别,从而确保了Ultllanplan。可靠性。为了将步骤级别重新编程功能,高频HBM高频HBM故障恢复时间减少到1分钟,并且故障使用户的计算机功率损失降低了5%。高可用性和支持业务:在OneClusteruse中的线性和训练速度恢复线性指标中的10亿型号,以衡量培训任务的最高速度或性能(即,完成时间减少),随着计算机馈电卡数量的增加。华为团队提出了四种主要技术,包括炸玉米饼拓扑合作的编排技术,网络StoraGE在网络级别和NSF计算的合并技术,通信技术增加了层次识别识别NB以及诊断技术和日期技术通信的测量,而无需入侵而无需入侵。一般计划如下图所示。实验和理论分析的结果表明,当训练Pangu Ultra 135B密度模型时,与卡256的基线相比,4K Atlas 800T A2卡群的线性是96%。当训练Pange Ultra Moe 718b的散射模型时,与800T A2的线性相比,群群的线性718B,与800T的线性相比,是8k的bacter 51 calbust。与256张卡的基线相比,4K卡的Matormatrix群集的线性度为96.48%。在大型AI组的操作过程中,几个硬件和软件故障经常中断培训任务。该行业通常使用CKPT来恢复培训任务,这些任务定期存储培训过程。华为创建了基于完整软件和硬件堆的以下S创新恢复和层次结构训练失败iSysms:下图显示了不同级别的灾难恢复功能。随着关键技术的优化,例如数据指数的构建加速度,模型汇编加速器,收集通信链的加速度,CKPT存储加速度,CA组的训练恢复时间可以在10分钟内实现。在过程级别进行重新编程的恢复可以进一步减少3分钟内的训练恢复。同时,可以将训练反转时间缩短为训练迭代时间,本质上独立于群集量表和模型量表,以及AI群集的可用性和出色的攀登量表非常有效地训练了效率。随着MOE模型架构的演变为1000亿,T该实例展示的网络体系结构已从机器中的八张传统卡演变为大型EP网络体系结构。当前,在大型EP网络体系结构下,主要问题是实现量表的扩展增加了故障概率数量并增加了故障半径。硬件故障使整个解码实例可用,从而导致推理服务中的损坏或中断。华为团队提出了芯片控制器层,框架层和平台层的合作,以响应出色的EP推理体系结构的可靠性问题,将解决方案重置为三层失败,实例中的切换和恢复,并在实例中恢复,并在最终创建And AndxTreemo的可靠性系统。不同的故障场景可以使用不同的容错恢复方法来最大程度地减少用户损失。其中,用I重新恢复恢复技术n该实例可以发展出皮带内快速故障的感知和重编程,预热和重量参数和镜子以及其他技术。实例内的重置恢复时间在5分钟内被压缩。对于KV HBM CACHE失败,Token DeepSeekv3级别保留技术基于1P2D多机云矩阵384场景,故障恢复时间(从失败到输出的重复使用时间)小于10秒。与行业的10分钟恢复案例相比,TLR可以将故障的影响减少60倍。关于AI计算机功率组的高可用性,华为团队提出了六个实用性效果:高可用性所必需的三个基本特征,例如识别和诊断故障,失败的管理和群集光链路故障中的失败和错误,以及三个关键支持特征,例如高可用性,例如高可用性,例如高可用性,例如高可用性。 t六项创新提供了可观的巨大好处,包括达到98%的CA组的可用性,最快的集群训练冲动速度达到了第二快速恢复的水平。由可观察,可衡量,智能,自主和环境极端的新工程范式代表的资源进步的Decigual and Pullin Fusion of Resources Edvances具有更具创新性的结果。编辑:Xu Yong Liang Chen
想象一下使用您的手机导航和计划长途路线。可能有数十个AI模型背后的道路条件分析并同时预测拥塞。如果医院使用AI来帮助诊断癌症,则该系统需要立即处理数百个CT图像。在这些看似简单的智能应用程序的背后,具体取决于AI的计算机功率组,即“超级脑”,以连续运行24小时。在比较具有大型工厂生产线的AI计算能力组时,它们提供了“永不击中”此生产线并为IA计算机电源组提供“安全”的能力,使该“数字发动机”每天都可以抵抗“小型打击和吹”,并在突然的障碍物发生时保持稳定的操作。只是保证可以提供资源Reporticos,并且可以连续可用生产成为促进商业创新的可靠引擎,而不是可以离开的“半生产产品”任何时候的业务。高可用性核心基金会:失败识别,管理,容错AI,超级新生儿的大组在系统,复杂的硬件和技术电池和长期挂钩的位置中很复杂。首先,交叉域故障的限制,然后是每个域内故障的内部故障的故障和定位。残疾的诊断面临着重要的挑战。当前的定位时间在小时到几天之间不等,由于技能要求高,很难找到错误的设备或根本原因。为了帮助集群操作和维护工具,请找到问题的原因,并有效提高现有网络问题的闭环效率,华为团队提出了可观察到的全电池的可观察特征,该特征主要由集群操作的操作视图,网络的监视,对NETW的访问监控的监视ORK和网络网络操作的视图以及网络操作的视图,网络操作的视图,网络操作网络的保留,网络网络操作视图,网络网络操作视图以及网络网络操作视图以及网络操作视图以及网络操作视图。同时,完整的种马还提出了拟议的故障诊断技术,其中包括四个主要功能,包括故障模式库,跨域失败的诊断,计算节点失败的诊断和网络失败的诊断。在ITCurrent行业级别,KA级AI组平均每天失败一次或多次。这不仅对培训效率产生了严重的影响,而且大大减少了计算机资源的浪费。为了解决这个问题,华为团队通过为AI组建立完整系统的可靠性分析模型来实现可靠性指标的预期评估和分配分解s。从分析,改进,可验证和诊断方面的方面,我们继续创建可靠的系统工程功能,破坏可靠性的关键技术,并提供Supernode CloudMatrix的Wankka群集MTBF硬件的高可靠性能力。 Supernodos需要爬上超级新星,以完全利用超平面网络的好处。当前,该行业没有成功使用光学链接消费超级新生儿,因此华为设备提出了相应的超级Nonod光学链路故障容忍度解决方案。通过多层保护系统,我们使用关键技术,例如超级时代和绿色通道,以确保在超发育不良水平上无法实现故障。在链接级别的重新启动,恢复光学模块,车道和HCCL操作员,提供了铁路通信,双层路由收敛,段落级别的重新编程和其他功能,以及ToleranCE的光学模块闪光破裂的故障费用为99%。在添加了超过10倍的光学模块后,通过测量软件的可靠性以及光学链路压力的测量技术,将光学模块的闪存中断速度降低到电气链路级别,从而确保了Ultllanplan。可靠性。为了将步骤级别重新编程功能,高频HBM高频HBM故障恢复时间减少到1分钟,并且故障使用户的计算机功率损失降低了5%。高可用性和支持业务:在OneClusteruse中的线性和训练速度恢复线性指标中的10亿型号,以衡量培训任务的最高速度或性能(即,完成时间减少),随着计算机馈电卡数量的增加。华为团队提出了四种主要技术,包括炸玉米饼拓扑合作的编排技术,网络StoraGE在网络级别和NSF计算的合并技术,通信技术增加了层次识别识别NB以及诊断技术和日期技术通信的测量,而无需入侵而无需入侵。一般计划如下图所示。实验和理论分析的结果表明,当训练Pangu Ultra 135B密度模型时,与卡256的基线相比,4K Atlas 800T A2卡群的线性是96%。当训练Pange Ultra Moe 718b的散射模型时,与800T A2的线性相比,群群的线性718B,与800T的线性相比,是8k的bacter 51 calbust。与256张卡的基线相比,4K卡的Matormatrix群集的线性度为96.48%。在大型AI组的操作过程中,几个硬件和软件故障经常中断培训任务。该行业通常使用CKPT来恢复培训任务,这些任务定期存储培训过程。华为创建了基于完整软件和硬件堆的以下S创新恢复和层次结构训练失败iSysms:下图显示了不同级别的灾难恢复功能。随着关键技术的优化,例如数据指数的构建加速度,模型汇编加速器,收集通信链的加速度,CKPT存储加速度,CA组的训练恢复时间可以在10分钟内实现。在过程级别进行重新编程的恢复可以进一步减少3分钟内的训练恢复。同时,可以将训练反转时间缩短为训练迭代时间,本质上独立于群集量表和模型量表,以及AI群集的可用性和出色的攀登量表非常有效地训练了效率。随着MOE模型架构的演变为1000亿,T该实例展示的网络体系结构已从机器中的八张传统卡演变为大型EP网络体系结构。当前,在大型EP网络体系结构下,主要问题是实现量表的扩展增加了故障概率数量并增加了故障半径。硬件故障使整个解码实例可用,从而导致推理服务中的损坏或中断。华为团队提出了芯片控制器层,框架层和平台层的合作,以响应出色的EP推理体系结构的可靠性问题,将解决方案重置为三层失败,实例中的切换和恢复,并在实例中恢复,并在最终创建And AndxTreemo的可靠性系统。不同的故障场景可以使用不同的容错恢复方法来最大程度地减少用户损失。其中,用I重新恢复恢复技术n该实例可以发展出皮带内快速故障的感知和重编程,预热和重量参数和镜子以及其他技术。实例内的重置恢复时间在5分钟内被压缩。对于KV HBM CACHE失败,Token DeepSeekv3级别保留技术基于1P2D多机云矩阵384场景,故障恢复时间(从失败到输出的重复使用时间)小于10秒。与行业的10分钟恢复案例相比,TLR可以将故障的影响减少60倍。关于AI计算机功率组的高可用性,华为团队提出了六个实用性效果:高可用性所必需的三个基本特征,例如识别和诊断故障,失败的管理和群集光链路故障中的失败和错误,以及三个关键支持特征,例如高可用性,例如高可用性,例如高可用性,例如高可用性。 t六项创新提供了可观的巨大好处,包括达到98%的CA组的可用性,最快的集群训练冲动速度达到了第二快速恢复的水平。由可观察,可衡量,智能,自主和环境极端的新工程范式代表的资源进步的Decigual and Pullin Fusion of Resources Edvances具有更具创新性的结果。编辑:Xu Yong Liang Chen